Follow up to Three wise men.
Solution to “three wise men”
A certain king wishes to determine which of his three wise men is the wisest. He arranges them in a circle so that they can see and hear each other and tells them that he will put a white or black spot on each of their foreheads but that at least one spot will be white. In fact all three spots are white. He then offers his favor to the one who will first tell him the color of his spot. After a while, the wisest announces that his spot is white. How does he know?
One way of visualizing the solution is to think hypothetical scenarios where some of the men have black spots in their foreheads. Lets start supposing that two of the men have black spots: then it will be obvious to the third that he has a white spot, as at least one of the three must have one.
Now suppose that only one of the men has a black spot and take the point of view of the “wisest” (quicker at least) man with a white spot. He cannot directly infer the color of his spot, as he sees one spot of each color. But, as we have seen in the last paragraph, the man in front of him with a white spot would have known the color of his spot if he (the observer) would have had a black spot in his forehead. As he didn’t speak, then he knows that the color of his spot must be white.
Finally, lets attack the full problem taking the place of the wisest man. He knows that, if he would have had a black spot in his forehead, one of the other men would have spoken, by the previously mentioned reasons. As they haven’t done that, he can conclude that the spot in his forehead must be white.
Blue eyed islanders puzzle
A similar, but more difficult, problem is the blue eyed islanders puzzle (this version was stolen from Terry Tao):
There is an island upon which a tribe resides. The tribe consists of 1000 people, 100 of which are blue-eyed and 900 of which are brown-eyed. Yet, their religion forbids them to know their own eye color, or even to discuss the topic; thus, one resident can see the eye colors of all other residents but has no way of discovering his own (there are no reflective surfaces). If a tribesperson does discover his or her own eye color, then their religion compels them to commit ritual suicide at noon the following day in the village square for all to witness. All the tribespeople are highly logical, highly devout, and they all know that each other is also highly logical and highly devout. One day, a blue-eyed foreigner visits to the island and wins the complete trust of the tribe. One evening, he addresses the entire tribe to thank them for their hospitality. However, not knowing the customs, the foreigner makes the mistake of mentioning eye color in his address, mentioning in his address “how unusual it is to see another blue-eyed person like myself in this region of the world”. What effect, if anything, does this faux pas have on the tribe?
Product & sum
This is another classical problem, first proposed (apparently) by Hans Freudenthal en 1959, and also called the “Impossible” Puzzle:
Given are X and Y, two integers, greater than 1, are not equal, and their sum is less than 100. S and P are two mathematicians; S is given the sum X+Y, and P is given the product X*Y of these numbers.
P says “I cannot find these numbers.”
S says “I was sure that you could not find them.”
P says “Then, I found these numbers.”
S says “If you could find them, then I also found them.”
What are these numbers?
Hint: a computer is very useful to solve this problem.
Solution for both puzzles in the next post.

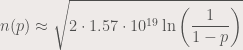 .
. .
.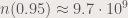 .
.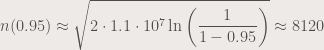 .
.