In this post we will analyse two exact algorithms to solve the Travelling Salesman Problem: one based on an exhaustive iteration through all the possible tours and another one using dynamic programming to reduce the asymptotic run time. Let’s start with the exhaustive one, as it’s easier.
Exhaustive O(n!) algorithm
We can number the cities from 0 to n and assume a distance matrix Di,j as given (the matrix doesn’t need to be symmetric, as it can reflect restrictions such as one-way roads). Then the code reduces to enumerating the tours (circular permutations of 0, 1, …, n) and selecting the one who has minimum length.
def tsp_naive_solve(d):
btl, best_tour = min((tour_len(t, d), t)
for t in permutations(range(1, len(d))))
return best_tour
itertools.permutations() is a Python primitive since the 2.6 version, but the internal implementation is explained in this excellent “Word Aligned” blog post.
Dynamic programming O(n 2n) algorithm
The first step (well, the first step that I do 😀 ) to make a dynamic programming algorithm for a problem is to get a recursive algorithm for the problem. In many cases, getting a recursive algorithm is just a matter of finding a formulation of the problem that matches useful subproblems. One example of a recursion-friendly presentation of the TSP is:
Get the path of minimum length that starts at city 0, passes through the set of cities 1 to n in any order and ends at city 0.
It’s fairly common that a more general version of a problem is easier to solve, and this is one of these cases. If we generalize the problem to:
Get the path of minimum length that starts at city 0, passes through a set of cities ts (not including i or 0) in any order and ends at city c.
we can make a straightforward recursive algorithm:
def rec_tsp_solve(c, ts):
assert c not in ts
if ts:
return min((d[lc][c] + rec_tsp_solve(lc, ts - set([lc]))[0], lc)
for lc in ts)
else:
return (d[0][c], 0)
where c represents the target city, ts is the intermediate set of cities and the next-to-last city is returned to allow reconstructing the path. Adding the reconstruction code:
def tsp_rec_solve(d):
def rec_tsp_solve(c, ts):
assert c not in ts
if ts:
return min((d[lc][c] + rec_tsp_solve(lc, ts - set([lc]))[0], lc)
for lc in ts)
else:
return (d[0][c], 0)
best_tour = []
c = 0
cs = set(range(1, len(d)))
while True:
l, lc = rec_tsp_solve(c, cs)
if lc == 0:
break
best_tour.append(lc)
c = lc
cs = cs - set([lc])
best_tour = tuple(reversed(best_tour))
return best_tour
Now that we have a recursive solution, we can add a memoization decorator to avoid recomputing and we get a dynamic programming algorithm. The set was replaced by a Python frozenset, because the function arguments must be “hashable” if the memoization decorator is going to be used.
The dynamic programming algorithm performance can be greatly improved by writing it in C, using bit operations to handle the cities’ set and building the partial results table iteratively from the bottom up. But all this techniques can only give us a constant improvement, with the asymptotic complexity remaining the same.
Performance comparisons
The performance tests consist just of running the 3 algorithms for problem instances containing from 2 to 10 cities. We get the following times in seconds running the test (the exact numbers are clearly system-dependent):
n naive time rec time dp time
2 7.2583e-06 1.6943e-05 2.0364e-05
3 1.8945e-05 4.7088e-05 5.0050e-05
4 7.5889e-05 1.7024e-04 1.3948e-04
5 4.0331e-04 7.9357e-04 3.9836e-04
6 2.5928e-03 4.6139e-03 1.1181e-03
7 1.9732e-02 3.1740e-02 3.0223e-03
8 1.6328e-01 2.4179e-01 8.0337e-03
9 1.5632e+00 2.1190e+00 2.1028e-02
10 1.6668e+01 2.0946e+01 5.2824e-02
To be able to see more easily the differences between the growth of these execution times, we can plot the data using matplotlib:

Running times as a function of the number of cities for each of the three algorithms.
It can be seen in the plot that the initially slowest algorithm, the one applying dynamic programming, ends up being more than one hundred times faster that the other two. As we are working with a semilog plot, the straight line of the DP algorithm is associated with approximately exponential growth, while the other algorithms show super-exponential growth.
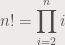


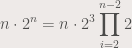
 ,
, .
.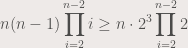
 .
.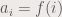 and monotonically growing
and monotonically growing  )
)

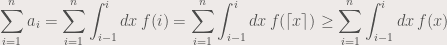
 .
. .
.
 .
.
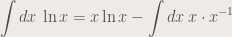

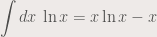 .
.
 .
. .
. .
.
 ,
,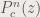 describes the polynomial resulting of iterating
describes the polynomial resulting of iterating  times the parameterized quadratic polynomial
times the parameterized quadratic polynomial 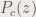 :
: .
. is infinite if for any positive number
is infinite if for any positive number  there is an element of the sequence
there is an element of the sequence 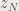 such that its module and the modules of all succeeding sequence elements are greater than
such that its module and the modules of all succeeding sequence elements are greater than  .
.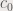 whose module is strictly greater than 2:
whose module is strictly greater than 2: .
.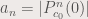 and
and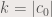 .
. .
. is non-negative. Let’s analyse carefully the relationship between a term and the previous one:
is non-negative. Let’s analyse carefully the relationship between a term and the previous one:


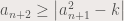 .
. , with
, with 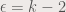 .
. 
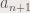 we get:
we get: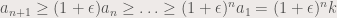





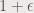 . Then any point
. Then any point  whose modulus is greater than 2 will be outside the set.
whose modulus is greater than 2 will be outside the set. 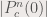 is greater than 2,
is greater than 2, 

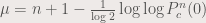 ,
, the “continuous” iteration count, the we get this picture:
the “continuous” iteration count, the we get this picture:

