It’s generally believed that it’s far too difficult to beat an optimizing C compiler when producing code, at least for a simple problem. In this post we will see how that’s not true and simple “hand-optimized” code can get large improvements in some cases.
Obviously that doesn’t mean that we should program using intrinsics or assembly most of the time: it still took me far more time to write this code than the time required to compile a C file with optimizations. But it means that, if we are working in a piece of time-critical code and profiling shows us a “hot spot”, it’s reasonable to consider doing such an optimization.
The problem
The problem description is very simple: given a big buffer (many megabytes), count the number of bytes equal to a given one. The prototype of such a function could be the following one:
size_t memcount(const void *s, int c, size_t n);
The baseline solution
Before doing any optimization is important to get a baseline solution and consider how optimal it is. In this case, it’s very easy to write:
size_t memcount_naive(const void *s, int c, size_t n)
{
const uint8_t *b = (const uint8_t *)s;
size_t count = 0;
for (size_t i = 0; i < n; i++)
if (b[i] == c)
count++;
return count;
}
Evaluating the baseline
We are going to do the evaluation with a relatively slow mobile Ivy Bridge core:
$ grep 'processor\|\(model name\)' /proc/cpuinfo processor : 0 model name : Intel(R) Core(TM) i5-3210M CPU @ 2.50GHz processor : 1 model name : Intel(R) Core(TM) i5-3210M CPU @ 2.50GHz processor : 2 model name : Intel(R) Core(TM) i5-3210M CPU @ 2.50GHz processor : 3 model name : Intel(R) Core(TM) i5-3210M CPU @ 2.50GHz
Timing with clock_gettime(), we get the following results:
$ gcc --version gcc (Ubuntu 4.8.4-2ubuntu1~14.04) 4.8.4 Copyright (C) 2013 Free Software Foundation, Inc. This is free software; see the source for copying conditions. There is NO warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. $ gcc -march=native -std=c11 -DTEST_NAIVE -O3 memcount.c -o memcount && ./memcount Generated random arrays. Count of character 45 in 'a1' using 'memcount_naive' is: 408978 Elapsed time: 103946325 ns Count of character 45 in 'a1' using 'memcount_naive' is: 408978 Elapsed time: 104022735 ns Count of character 45 in 'a2' using 'memcount_naive' is: 409445 Elapsed time: 104278289 ns Count of character 45 in 'a3' using 'memcount_naive' is: 410593 Elapsed time: 104127038 ns Count of character 45 in 'a4' using 'memcount_naive' is: 104447433 Elapsed time: 104110155 ns Count of character 45 in 'a5' using 'memcount_naive' is: 104857613 Elapsed time: 104122294 ns
The measured time to count bytes with a given value in a ~100 MB array is about 100 ms, giving us a processing speed of approximately 1 GB/s. There are no substantial caching effects, as expected given that we are processing a 100 MB array.
Can we do better?
Memory bandwidth
Let’s start by calculating the memory bandwidth. We can get the memory parameters by using the dmidecode command:
$ sudo dmidecode --type 17 | grep '\(Locator\)\|\(Clock\)\|\(Size\)\|\(Type\)' Size: 4096 MB Locator: ChannelA-DIMM0 Bank Locator: BANK 0 Type: DDR3 Type Detail: Synchronous Configured Clock Speed: 1333 MHz Size: No Module Installed Locator: ChannelA-DIMM1 Bank Locator: BANK 1 Type: Unknown Type Detail: None Configured Clock Speed: Unknown Size: 4096 MB Locator: ChannelB-DIMM0 Bank Locator: BANK 2 Type: DDR3 Type Detail: Synchronous Configured Clock Speed: 1333 MHz Size: No Module Installed Locator: ChannelB-DIMM1 Bank Locator: BANK 3 Type: Unknown Type Detail: None Configured Clock Speed: Unknown
We have two DDR3 DIMMs in separate channels, running at “1333 MHz”. The expected bandwidth would be:
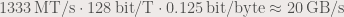
so we should have plenty of room for improvement. We can get a more realistic upper limit by comparing the performance to a highly optimized normal operation, such as memchr():
$ gcc -march=native -std=c11 -DTEST_MEMCHR -O3 memcount.c -o memcount && ./memcount Generated random arrays. Timing 'memchr()' to get character 13' in 'a5'. Result: (nil) Elapsed time: 6475968 ns Timing 'memchr()' to get character 13' in 'a5'. Result: (nil) Elapsed time: 6919187 ns
Now we know that bandwidths of ~14 GB/s are achievable in this system, so there should be plenty of room for improving performance.
Using SSE intrinsics
My solution (that is probably far from optimal) is the following one:
size_t memcount_sse(const void *s, int c, size_t n)
{
size_t nb = n / 16;
size_t count = 0;
__m128i ct = _mm_set1_epi32(c * ((~0UL) / 0xff));
__m128i z = _mm_set1_epi32(0);
__m128i acr = _mm_set1_epi32(0);
for (size_t i = 0; i < nb; i++)
{
__m128i b = _mm_lddqu_si128((const __m128i *)s + i);
__m128i cr = _mm_cmpeq_epi8 (ct, b);
acr = _mm_add_epi8(acr, cr);
if (i % 0xff == 0xfe)
{
acr = _mm_sub_epi8(z, acr);
__m128i sacr = _mm_sad_epu8(acr, z);
count += _mm_extract_epi64(sacr, 0);
count += _mm_extract_epi64(sacr, 1);
acr = _mm_set1_epi32(0);
}
}
acr = _mm_sub_epi8(z, acr);
__m128i sacr = _mm_sad_epu8(acr, z);
count += _mm_extract_epi64(sacr, 0);
count += _mm_extract_epi64(sacr, 1);
for (size_t i = nb * 16; i < n; i++)
if (((const uint8_t *)s)[i] == c)
count++;
return count;
}
Testing it we get substantially better times:
$ gcc -march=native -std=c11 -DTEST_SSE -O3 memcount.c -o memcount && ./memcount Generated random arrays. Count of character 45 in 'a1' using 'memcount_sse' is: 408978 Elapsed time: 10908773 ns Count of character 45 in 'a2' using 'memcount_sse' is: 409445 Elapsed time: 11195531 ns Count of character 45 in 'a3' using 'memcount_sse' is: 410593 Elapsed time: 12147576 ns Count of character 45 in 'a4' using 'memcount_sse' is: 104447433 Elapsed time: 10930570 ns Count of character 45 in 'a5' using 'memcount_sse' is: 104857613 Elapsed time: 10856319 ns
The new speeds are between 8 and 9 GB/s, almost an order of magnitude faster than the “naive” code.
Explanation
As this is my first program using intrinsics, it’s probably far from optimal. But, as it can seem pretty impenetrable, let’s explain it step by step.
Initialization
size_t memcount_sse(const void *s, int c, size_t n)
{
size_t nb = n / 16;
size_t count = 0;
__m128i ct = _mm_set1_epi32(c * ((~0UL) / 0xff));
__m128i z = _mm_set1_epi32(0);
__m128i acr = _mm_set1_epi32(0);
This section just initializes some variables:
- nb: we will process the input in blocks of 16 bytes (128 bits), so we use this variable to track the number of blocks to be processed.
- count: the return value, to be filled with the byte count to be computed.
- ct: the comparison target, a 128 bit value filled with copies of c, the byte value we are counting.
- z: a zero 128 bit value.
- acr: the accumulated comparison result, a 128 bit value that accumulates the comparison results in a special format, to be described later.
Only one intrinsic is used here, _mm_set1_epi32(). It loads repeated copies of a 32 bit value in a 128 bit value.
Comparing and accumulating
for (size_t i = 0; i < nb; i++)
{
__m128i b = _mm_lddqu_si128((const __m128i *)s + i);
__m128i cr = _mm_cmpeq_epi8 (ct, b);
acr = _mm_add_epi8(acr, cr);
The loop is self explanatory: we are just iterating over 128 bit blocks. The next intrinsic, _mm_lddqu_si128() just loads a potentially unaligned 128 bit value into the 128 bit variable b.
Now comes the key section: we compare b byte per byte against the comparison target ct, using the intrinsic _mm_cmpeq_epi8(), and we store 0xff when the bytes match and 0x00 when they don’t in the comparison result cr. That result is summed byte per byte in the accumulated counts variable acr, with the intrinsic _mm_add_epi8().
As 0xff is -1 modulo 256, the accumulation works normally, but we could have an overflow after 256 iterations. To avoid that, we need to move this counts to our count variable periodically.
Definitive accumulation
if (i % 0xff == 0xfe)
{
acr = _mm_sub_epi8(z, acr);
__m128i sacr = _mm_sad_epu8(acr, z);
count += _mm_extract_epi64(sacr, 0);
count += _mm_extract_epi64(sacr, 1);
acr = _mm_set1_epi32(0);
}
Every 255 iterations (to avoid overflow), we do the following operations:
- Change the sign of
acrby subtracting it from zero to get the positive values of the counts (using the_mm_sub_epi8()intrinsic). - Get the absolute value of each byte and sum all these values to get the total count (using the
_mm_sad_epu8()intrinsic, that leaves the sum split in the low and high parts of the 128 bit variable). - Sum the low and high parts of the 128 bit variable to
count, to get the total count, using the_mm_extract_epi64()intrinsic to get those parts. - Set the accumulated comparison result
acrvariable to zero.
After loop accumulation
acr = _mm_sub_epi8(z, acr);
__m128i sacr = _mm_sad_epu8(acr, z);
count += _mm_extract_epi64(sacr, 0);
count += _mm_extract_epi64(sacr, 1);
Accumulates the value that remains in acr after exiting the main loop.
Bytes after last block
for (size_t i = nb * 16; i < n; i++)
if (((const uint8_t *)s)[i] == c)
count++;
return count;
}
Handles the bytes that come after the last 16 byte block and returns the total count.
Conclusion
We have seen that a substantial improvement of almost 10x can be obtained over the optimizing compiler results, even in cases where the code to be optimized is quite simple. It would be interesting to see how close to the 20 GB/s we can get with more carefully optimized code…
The code used for these tests is available in Github.

You could try adding some data prefetch instructions
So it looks like using a more modern compiler and some hand-holding closes the gap. GCC 5.2 and Clang 3.7 generate vectorized comparison instructions for the naive version and so it runs in only twice the time as the SSE version at -O3 optimization level on my machine.
So, I figured that the compiler was probably adding up the result of the SSE register every loop iteration to prevent overflow, and perhaps it was struggling with the uint8_t-int comparison, so I fixed those, and here is the result.
size_t memcount_naive(const void *s, int c, size_t n)
{
uint8_t cc = c;
const uint8_t *b = (const uint8_t *)s;
size_t count = 0;
size_t i = 0;
for (; i < n – 224; i += 224) {
uint8_t tempcount = 0;
for (int j = i; j < i + 224; j++)
if (b[j] == cc)
tempcount++;
count += tempcount;
}
for (; i < n; i++) {
if (b[i] == c)
count++;
}
return count;
}
With both compilers, the code has nearly identical performance with the your SSE code on my machine.
Of course, creating this code requires knowledge of how compilers work and of the machine instructions that the compiler is using, and may be harder than using intrinsics or inline asm for people who are stuck with old compilers or do not want to learn about compilers.
Nice solution!
Yes, probably using a relatively old compiler was a bit unfair, but it was mostly an excuse to learn more about SSE (I found about the problem while trying to write a parallel CSV parser and finding the skeleton pass was much slower than expected).
I agree that, in general, it’s better to write “optimizable” C code. Though sometimes the fragility of optimizations can be a problem.
The fastest sse memcount on my pc. >80% faster than original sse memcount: https://gist.github.com/powturbo/456edcae788a61ebe2fc
The fastest sse memcount on my pc. 2 times faster than original sse memcount: https://gist.github.com/powturbo/456edcae788a61ebe2fc
Thanks! Seems unrolling & prefetching are the key improvements.